how to read a ML paper (with maths)
I generally choose papers based on the requirements I have at the moment or when I find something interesting. I started reading papers on physics and eventually adapted to reading ML papers. If you’re just starting with papers, I’d recommend selecting a less math-intensive one.
Step 1: Choosing a Paper
The first step is simply deciding what to read. I usually find paper suggestions from X, and I often visit the sites of top research labs and navigate their Publications section. As we know, arXiv is the best place to find papers. Recently, I tried AlphaXiv, but it didn’t work much for me, so I stick with the usual reading method.
some labs i usually look upon,
AI2 - https://allenai.org/papers
ByteDance - https://seed.bytedance.com/en/research
DeepSeek - https://huggingface.co/collections/Presidentlin
DeepMind - https://deepmind.google/research/publications/
If you’re looking for a read-list, you could checkout my ai-reading-list
Step 2: Skimming Content
Once I have a paper, I begin with a quick skim. I read the abstract and introduction to understand the core idea, what the paper is about, and whether they improved an existing method (sometimes you’ll be reading FlashAttention 2 without even reading FlashAttention) or introduced something entirely new.
The second thing I pay attention to is the architecture diagram. Here, I check whether I’m already familiar with the approach or the terms they use. If not, I pause and look up the terms before continuing.
The last part I skim is the datasets and results. This gives me a clearer view of what they attempted and what they ultimately achieved. Datasets, in particular, tell you a lot about the architectural effort or system requirements. After all, processing a trillion tokens is not a simple task.
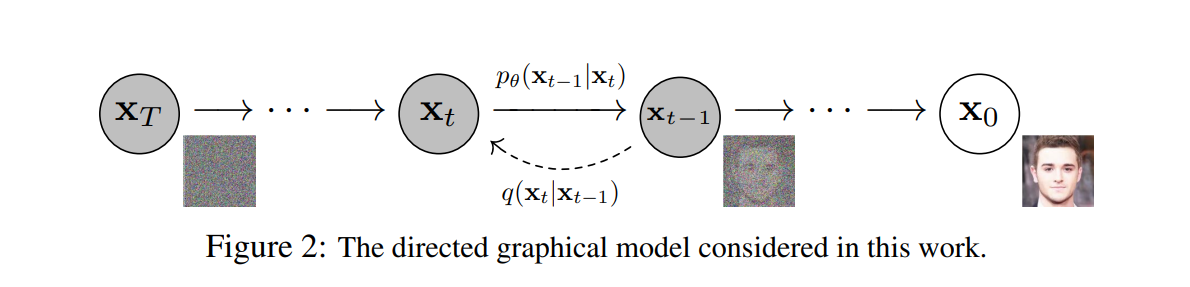
Reading diagrams while skimming is one of the effective way to find out if you're clear with what you're reading

These Algorithm sections must be read before start doing math. This defines which part of the paper plays an important role and which is not. So, you could generate sample problems accordingly.
Step 3: Start Reading
Once the skim is done, I dive deeper. I usually take a day or two to properly read a paper depending on its complexity. Some are quick and straightforward, like ByteDance’s Let the Code LLM Edit Itself When You Edit the Code, which I finished in around 2 hours. Others are much heavier, for example Denoising Diffusion Probabilistic Models took me 4 days to fully work out.
After completing the introduction, I move on to related work and then into the architectural explanation. The most time-consuming part is almost always the architecture and mathematics.
what if I don’t understand something?
In that case, I upload the paper to Gemini-2.5-Pro and use a prompt like this to generate a story-like context:
Understand the paper and assign characters to the concepts involved in it. Generate a story-like flow explanation where each character represents a key idea or method, and their interactions represent the logical flow of the paper. The goal is to create a narrative that makes the entire paper easy to follow, while still preserving the technical accuracy of the concepts.
I then read this generated story to get a clearer sense of how the whole paper flows. This makes it easier to understand where I should focus more and where I can afford to care less.
Step 4: Beating around the bushes
The architecture section in most papers is high-level and often simplified beyond abstraction. People who aren’t strong with math may find it difficult to push through this section. Normally, “beating around the bushes” isn’t a great practice, but in my case, reading around the paper and diving into surrounding material works better.
To deal with the heavy math, I follow few personal techniques.
Learning by derivation
I upload the mathematical part of the paper to Gemini-2.5-Pro and discuss the core concepts. From there, I generate 5–10 derivation-style questions based on the math.
A useful prompt here is:
From the mathematical sections of this paper, generate a set of 5–10 step-by-step derivation exercises. Each question should start from first principles and gradually work toward the equations given in the paper. The goal is to practice re-deriving the results, not just copying them, so make sure each exercise highlights the reasoning behind the steps.
I take my time, usually a day, to work through these derivations carefully, step by step.
[If you have doubts, open another chat and discuss them separately (gemini-2.5-flash).]

Tasks generated from the [Denoising Diffusion Probabilistic Models] paper.
Learning by solving
The next step is to test my understanding. Here, I generate another set of 5–10 solution-based questions from the paper’s concepts.
The prompt I use is:
From the concepts discussed in this paper, create 5–10 application-style problems. Each problem should ask me to apply the equations, algorithms, or methods to a specific scenario (e.g., working with a tensor, applying a Hessian, or analyzing a result). The problems should vary in difficulty and require detailed solutions, so I can check how well I’ve understood the material.
It’s easy to just read and say, “ok, this returns an n-d tensor and then we perform Hessian over this.” But once you actually solve problems, you realize how much you’re missing in minimal yet crucial details.
These two steps, derivation and solving, are how I usually break down the mathematical part of any paper.

Problems generated from the [Denoising Diffusion Probabilistic Models] paper.
Learning by engineering
Finally, after reading and understanding, I try to code the paper in my free time. Most of the time I attempt it on my own, but if I get stuck, I’ll refer to the official repository first.
[AI-generated implementations can work, but the code quality, efficiency, and handling of edge cases are often compromised. So, always check the official repo first. If none is available, you can use AI to assist in sections you’re unsure of.]
For finding implementations, I rely on HuggingFace Papers. (PaperswithCode ceased their operations last week)
- For models: I use PyTorch or JAX
- For kernels: I use Triton
Final Note
You might think this much effort is not needed to read a paper, but it actually is. To read a paper with ease, you either need years of reading experience and familiarity with the terms, or you need to put in time learning them. Never take the math lightly, invest a lot of time in your 20s learning math and physics. That foundation will pay off later.
For me, it happened naturally over time. I had been reading cosmology papers since I was 15, and that background eventually made my transition into AI smoother. So, just keep on doing these, it’ll help you a lot later.