Kimi - 1.5 B
We have all been familiar with these LLM models since 2022, and today, we have a new model that works better and more efficiently than its counterparts (not the deep seek, the other one). It’s Kimi 1.5 B. I’ve been waiting for this model since the launch of its paper in arXiv. I wanted to make this blog earlier but couldn’t due to some work.
We’ll learn how Kimi works as simply as possible, with maybe a little bit of math in between.
Paper - Kimi 1.5B Paper
Try it out - www.kimi.ai
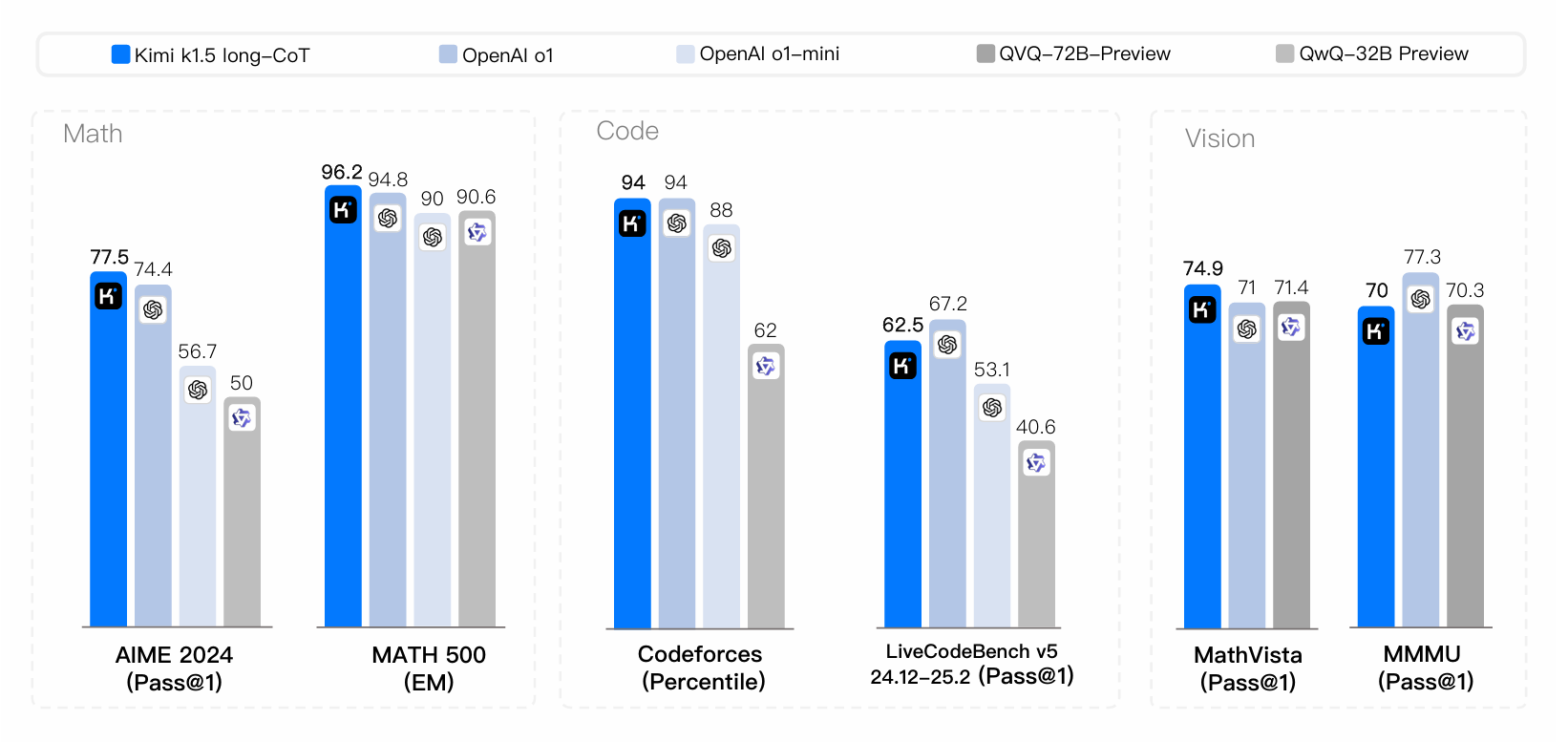
Kimi SOTA Benchmark
THE LLM’s
I would probably assume that you know what’s an LLM. If not, LLM is a model that generates human-like text by calculating the probability of a word occurring next to the given word. After this, we’ve added a lot of reasoning methods, fine-tuning techniques, and a lot of others to make it more and more human.
But after all, it’s probability. That’s where Kimi (of course, deepseek too) made a change. They came up with this well-known fact, “learning is better than memorization,” and put it up in their extra GPUs and made Kimi. Simply, they implemented Reinforcement learning to scale its reasoning and mathematical ability, which most of the current models do by brute force COT (Chain of thought).
Guys, this article would be partially latex, as I’m countering some issues with MathJax and Katex rendering. Will be fully latex from next blog.
The Kimi Recipe:
-
Pretraining: RL Prompt set curation
Initially, an RL prompt set was created from the large corpus of text data. Here, we have to notice something cool. We all faced this. Like, whenever we ask a simple question, most thinking models spend a lot of time figuring out the answer. Kimi solves this issue by removing this set of simple problems from the pre-training dataset and then reducing the number of prompt attempts to less than 8.
-
CoT Supervised Fine Tuning (SFT):
In this step, Kimi is given the sample warmup dataset with long CoT with correct answers and reasons for both text and image inputs. A lightweight SFT is used to internalize the training strategies, which results in coherent responses.
-
Reinforcement Learning:
3.1 Problem Setting
They initially trained a policy model $ \pi_\theta $ to solve complex reasoning tasks using the Chain of Thought (CoT) methodology, reinforcement learning, and planning algorithms. We’ll hop one by one,
3.1.1 Chain of Thought (CoT)
CoT introduces a structured reasoning process where the model generates intermediate steps $ z = (z_1, z_2, \dots, z_m) $ to bridge the problem $ x $ to the solution $ y $.
At each step $ t $, the thought $ z_t $ is sampled as: $ z_t \sim \pi_\theta(\cdot \mid x, z_1, \dots, z_{t-1}) $
Finally, the solution $ y $ is sampled as: $ y \sim \pi_\theta(\cdot \mid x, z_1, \dots, z_m) $
The model learns to generate $ z $ and $ y $ as part of a coherent sequence of tokens.
This method is similar to how we look up lost things. Instead of thinking where we had placed our pencil or key, we’d just think, “What are the events we used our key recently? What have we done after that? ”
3.2. Planning Algorithms
3.2.1 Goal
Planning algorithms explores reasoning paths by constructing a search tree of thoughts $ T $, just as we seen eariler in COT. In the created Tree $ T $,
Each node represents a partial solution: $ s = (x, z_{1:|s|}) $, where $ |s| $ is the number of thoughts.
These nodes are evaluated by a critic Model $ v(x, z_{1:|s|}) $ that evaluates each partial solution for progress and errors. They even backtrack and correct if becomes necesaary.
3.2.2 Algorithm Perspective
Given previous search history, a planning algorithm $ A $ maps: $ A(s_t \mid s_1, v(s_1), \dots, s_{t-1}, v(s_{t-1})) $ to determine the next search step or provide feedback.
3.2.3 Flattened Representation
Instead of explicitly building a search tree, planning is approximated as sequential token generation using long-context reasoning. This avoids the need for complex parallel tree expansions.
3.3 Reinforcement Learning (RL)
3.3.1 Reward Model $ r(x, y, y^*) $
The reward model $ r(x, y, y^*) $ evaluates whether the model’s output ‘y’ aligns with the ground truth. We could define the correctness by these two techniques,
- Predefined rules: For coding tasks, correctness is determined by whether the output passes all test cases.
- Trained models: For open-ended (general) tasks, the reward model predicts correctness based on labeled data.
The reward is binary:
$$ r(x, y, y^*) \in {0, 1} $$
3.3.2 Objective Function
The policy $\pi_\theta$ is trained to maximize the expected reward:
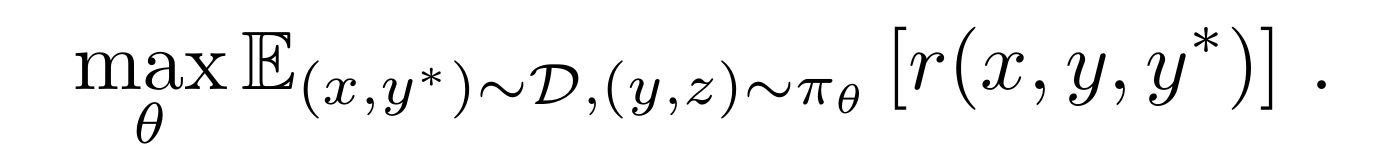
Objective function
This optimization allows the model to generate reasoning paths $z$ that lead to correct answers $y$ by maximing the rewards for efficient solutions.
3.3.3 Policy Optimization and Penalization:
One of the most crucial aspects of policy optimization is penalization. We have to be careful about what we label as a negative. Let’s think of the scenario, where you get to a correct answer despite thinking in a flawful way. More like, “Task Failed successfully”. Do we penalize an LLM for doing this?
As by Standard Penalization strategies, we do. But in Long CoT, as long as the model reaches the final correct state, it’s free to explore lengthy conversations and paths, as they heavily influence the model to be much more context-aware. At the same time, we have to restrict the model’s thinking capability by adding a penalty factor if it keeps working on excessive token lengths.
It’s good to explore until it sucks out your funds and GPUs. For this, we do a simple trick of allowing long CoT is early phases of training, then gradually implementing length penalty in the full training phase.
For a problem $x$ with true answer $y^*$, let there be $k$ sampled responses $(y_1, z_1), …, (y_k, z_k)$, where the length of a response $(y_i, z_i)$ is denoted as $\text{len}(i)$. Let:
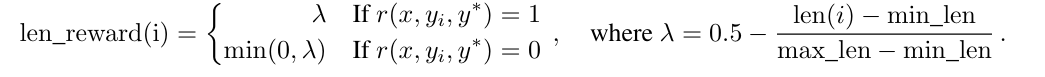
Length Penalty
Later, sampling techniques were found to be helpful in efficient problem solving as they allow the models to read the labels of the problems and act accordingly. The model would look for more complex connections in a topology problem than it does in a simple High school calculus.
Training and Others
Maybe, we don’t need it. Just we’re going to stick with the architecture for now. Lemme know if you want me to do one for training.
Conclusion
Bye.