does mid-training help language models to reason better?
Paper: arxiv.org/pdf/2506.20512
Hugging Face: huggingface.co/OctoThinker
GitHub: github.com/GAIR-NLP/OctoThinker
Let’s say we have a powerful base model and attempt to apply RL strategies to improve its reasoning and performance on mathematical questions. However, once RL training begins, we might observe the model getting stuck in a loop, repeating tokens endlessly, leading to inflated context lengths and invalid answers.
OctoThinker observes that not every model is naturally suited for RL. To make a model compatible with RL, we must focus on a largely underlooked phase of model training: mid-training. A new paper from GAIR Lab, “OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling,” explores this phenomenon in depth and proposes a powerful recipe for making models “RL-ready.”
the Problem:
The researchers at GAIR Lab started by confirming the problem: Llama-3.2 models struggle with R1-Zero-style RL training for math reasoning. When prompted to solve problems, they often produce repetitive, nonsensical outputs and fail to improve. In contrast, Qwen2.5 models learn steadily and show significant performance boosts.
The core hypothesis is that a model’s suitability for RL is determined by its pre-training history. Inorder to solve this issue, they introduce a phase called, ‘mid-training’.
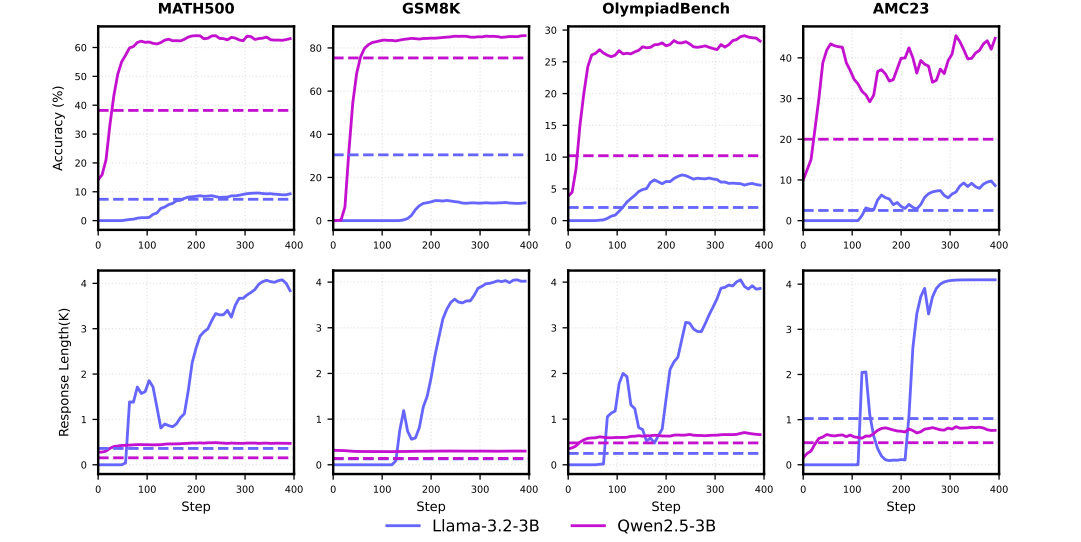
Training dynamics comparison between Llama-3.2-3B and Qwen2.5-3B
what is Mid-training?
It’s a mid-stage whose computational and data requirements are intermediate between pre-training and post-training. It aims to achieve specific objectives like improving data quality, expanding to new domains, or preparing for post-training by significantly altering the data distribution.
dataset Curation
| Dataset | Type | Tokens (B) |
|---|---|---|
| FineMath-4plus (Allal et al., 2025) | Math Web Documents | 9.57 |
| MegaMath-Web-Pro (Zhou et al., 2025) | Math Web Documents | 13.00 |
| MegaMath-Web-Pro-Max (Ours) | Math Web Documents | 73.80 |
| MegaMath-QA (Zhou et al., 2025) | QA (Short-CoT) | 5.94 |
| OpenR1-Math-220K (HuggingFace, 2025) | QA (Long-CoT) | 1.05 |
| TULU3-sft⋄ (Lambert et al., 2024a) | General Instruction Following | 0.01 |
| WildChat (Zhao et al., 2024) | General Instruction Following | 0.29 |
| UltraChat-220K (Ding et al., 2023a) | General Instruction Following | 0.51 |
in simple terms
1) CoT is essential for reasoning, but the type of CoT matters immensely.
- Long CoT data, with its deep, multi-step reasoning, is powerful but volatile.
It can cause a “response length boom,” where the model generates repetitive, low-quality text until it hits the context limit. - Short CoT data is far more stable. It teaches the model to reason concisely, keeping the response length in check and maintaining a focus on correctness.
2) General instruction data as a stabilizer
- Long CoT eventually becomes uncontrollable during RL training.
- In order to control this, a small dose of general instruction-following data is given.
- They mixed in a tiny 1% portion of instruction data with their web and QA data, creating a 1:89:10 ratio.
The instruction data unlocks the full potential of the short reasoning examples, leading to significant and stable performance gains after RL training.
However, it is ultimately not enough to prevent a collapse with Long-CoT.
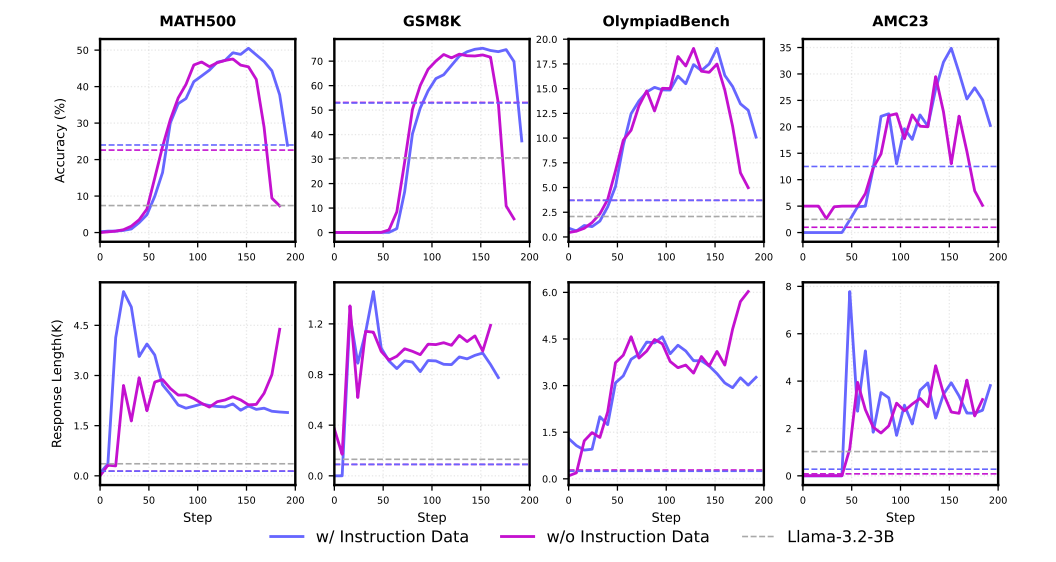
Impact of incorporating instruction-following data during mid-training with a mixture of web, long-CoT and instruction data in a ratio of 89: 10: 1
3) More Mid-training tokens improve RL potential
Scaling mid-training from 20B to 100B tokens didn’t always increase base model performance, but consistently improved downstream RL performance.
The more you invest in high-quality mid-training, the higher the performance ceiling for RL.
Impact of scaling up the mid-training budget
What 'OctoThinker' Does to Mitigate the Issues ?
1) The Stable Stage (Building Foundation)
First, the base Llama model is trained for a massive 200 billion tokens on a high-quality data mix (as in the previous table). This is done with a constant learning rate to build a knowledge-rich foundation without specializing too early.
2) The Decay Stage (Branch Out 'Arms' and Train)
From the single, stable base, they “branch” out into multiple variants trained for another 20 billion tokens with a decaying learning rate. Each branch is fed a different data diet to create diverse reasoning styles:
- OctoThinker-Long: Rich in long-CoT data for deep reasoning
- OctoThinker-Short: Focused on short-CoT data for concise problem-solving
- OctoThinker-Hybrid: A balanced mix of both
[A decaying learning rate is perfect for specialization. It allows the model to make large, adaptive updates at the beginning to quickly absorb the new, targeted data mix, and then smaller, more precise updates as it refines its behavior.]
data Mixtures in the Decay Stage
(a) Long Branch Mixture
| Dataset | Weight |
|---|---|
| DCLM-Baseline | 0.05 |
| Instruction Following | 0.10 |
| MegaMath-Web-Pro | 0.55 |
| Open R1 | 0.15 |
| AM-DeepSeek-Distilled-40M | 0.15 |
(b) Short Branch Mixture
| Dataset | Weight |
|---|---|
| DCLM-Baseline | 0.05 |
| Instruction Following | 0.10 |
| MegaMath-Web-Pro | 0.55 |
| MegaMath-QA | 0.025 |
| OpenMathInstruct2 | 0.175 |
| NuminaMath1.5 | 0.10 |
(c) Hybrid Branch Mixture
| Dataset | Weight |
|---|---|
| DCLM-Baseline | 0.05 |
| Instruction Following | 0.10 |
| MegaMath-Web-Pro | 0.55 |
| OpenMathInstruct2 | 0.10 |
| NuminaMath1.5 | 0.10 |
| Open R1 | 0.10 |
conclusion
The final RL-tuned OctoThinker models, which originated from Llama, effectively close the performance gap with the RL-friendly Qwen2.5 models on math reasoning benchmarks, which the base version couldn’t even come close to.
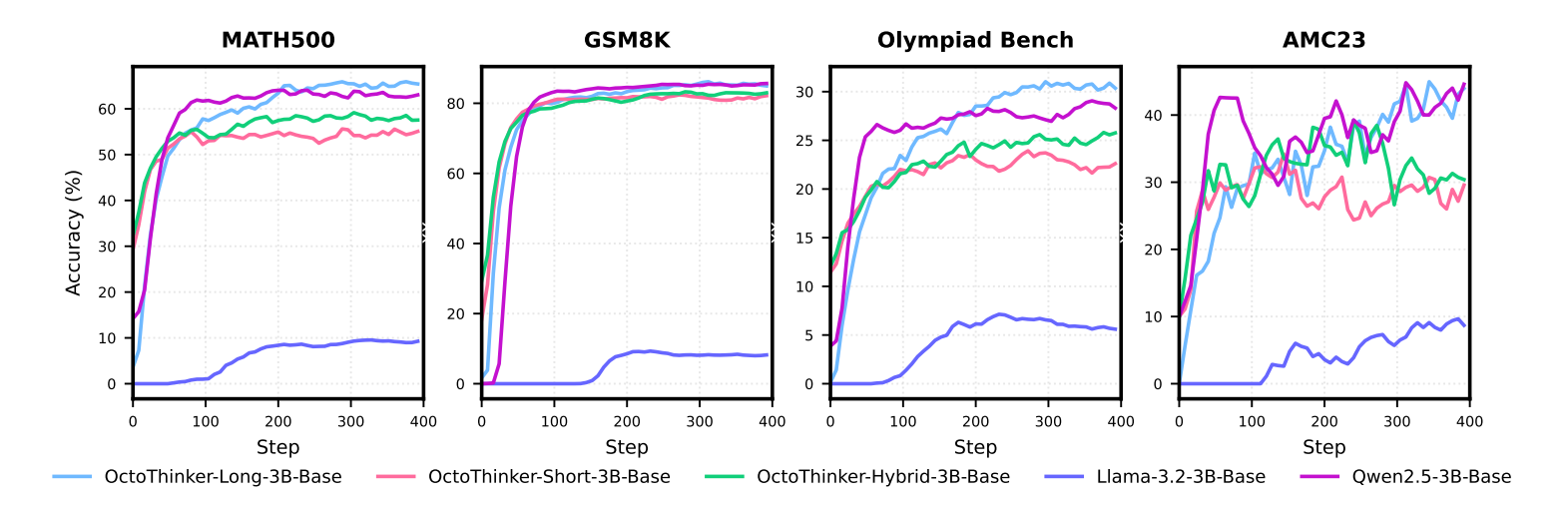
RL training dynamics among Llama-3.2-3B-Base, OctoThinker series and Qwen2.5-Base.